· Hien · 5 min read
ChatGPT's Real Session ID Isn't Where MCP Says It Should Be
ChatGPT throws away the standard MCP session on every tool call. But it carries its own session ID inside the JSON-RPC body, in a place no header-based proxy can see. Here's where it lives, why OpenAI put it there, and how mcpr surfaces it.
This is part 2. Part 1 showed that ChatGPT issues a fresh Mcp-Session-Id for every tool call, while Claude reuses one. That makes the standard MCP session header useless for grouping ChatGPT activity. This post answers the obvious follow-up: how do you correlate a ChatGPT user across tool calls?
The short answer: ChatGPT carries a stable correlation ID in the JSON-RPC body, on params._meta. Six fields, all under the openai/ prefix. Per OpenAI’s Apps SDK reference:
openai/session: “Anonymized conversation id for correlating tool calls within the same ChatGPT session”openai/subject: “Anonymized user id sent to MCP servers for the purposes of rate limiting and identification”openai/organization: “Anonymized organization id associated with the current ChatGPT organization, when available”openai/locale: e.g.en-US,vi-VNopenai/userAgent: client UA stringopenai/userLocation:{ city, country, latitude, longitude, timezone }
On the wire it looks like this:
{
"jsonrpc": "2.0", "id": 47, "method": "tools/call",
"params": {
"name": "create_matching_question",
"arguments": { ... },
"_meta": {
"openai/session": "v1/abc123...",
"openai/subject": "v1/user_xyz...",
"openai/organization": "v1/org_...",
"openai/locale": "en-US",
"openai/userAgent": "Mozilla/5.0 ...",
"openai/userLocation": {
"city": "Vũng Tàu", "country": "VN",
"latitude": "10.34599", "longitude": "107.08426",
"timezone": "Asia/Ho_Chi_Minh"
}
}
}
}openai/session is the one you want for correlation. Unlike Mcp-Session-Id, it does not rotate per tool call; it’s stable for the conversation.
OpenAI’s docs are explicit on a second point: none of these fields are usable for authorization. They’re hints. The subject is what OpenAI tells you the user is, not a verified identity.
Why OpenAI put it there
Three reasons, all sourced from OpenAI’s own docs and the MCP spec.
1. ChatGPT is architected to be stateless across tool calls. OpenAI’s build guide tells server authors that tools “should be idempotent - the model may retry calls” and that “tool inputs [should be] explicit and required for correctness; do not rely on memory for critical fields.” Session-per-call is the strongest possible expression of that principle. With no per-session state to preserve, ChatGPT can route any tool call to any backend, restart workers freely, and scale horizontally without sticky sessions. The cost: Mcp-Session-Id becomes meaningless as a correlation key, because there’s no logical session for it to point at.
2. The conversation is the session, and conversations live above MCP. ChatGPT’s notion of “session” is a chat conversation, not an MCP transport connection. openai/session is documented as a conversation id. The conversation outlives any individual transport session; it has to ride in the request body because no transport-layer header can span what is, by design, many transports.
3. _meta is the spec-sanctioned place for this. The MCP spec reserves _meta for protocol extensions, with a prefix/name key format. Prefixes containing mcp or modelcontextprotocol are reserved for the spec itself; everything else is open for clients and servers. openai/... is exactly the pattern the spec was designed for. There’s also a useful side effect that OpenAI calls out directly: _meta is “delivered only to the component, hidden from the model.” Putting correlation IDs there keeps them out of the LLM’s context window, where they’d waste tokens and risk being echoed back in responses.
The 2026 MCP roadmap is now explicitly moving the spec toward stateless transports. OpenAI’s session-per-call shape is ahead of where the spec is going.
Why a header-only proxy can’t see this
Mcp-Session-Id lives on the HTTP envelope. Any reverse proxy can read it without parsing the body. openai/session lives inside the JSON-RPC body on params._meta. To read it you need to parse the body as JSON, validate the JSON-RPC envelope, and reach into a nested object. nginx and HAProxy can’t. A JSON-RPC-aware proxy that doesn’t know the Apps SDK extension will see the field but won’t know it’s the correlation key.
What we changed in mcpr
The extractor lives in mcpr-core/src/event/openai.rs:
pub struct OpenAiClientContext {
pub session_id: Option<String>,
pub subject_id: Option<String>,
pub organization_id: Option<String>,
pub locale: Option<String>,
pub user_agent: Option<String>,
pub user_location: Option<Value>,
}If none of the six keys are present, the parser returns None and non-ChatGPT clients pay zero. Batch JSON-RPC requests read _meta from the first rpc; per OpenAI, conversation-level metadata is shared across the batch.
On the cloud side, each log entry now carries the OpenAI metadata alongside the standard MCP fields:
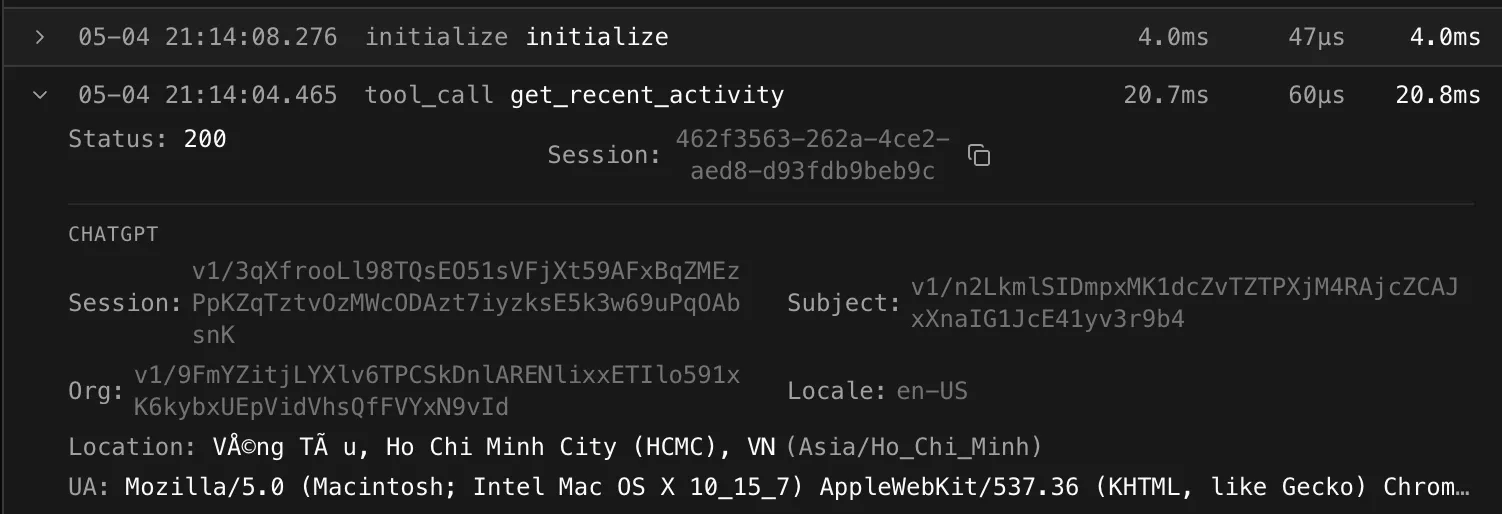
The logs UI accepts the same names as filterable facets, so you can group a whole ChatGPT conversation by openai_session instead of chasing rotating MCP session IDs:
openai_session:v1/abc123 # one ChatGPT conversation
openai_subject:v1/user_xyz # one user across conversations
openai_org:v1/org_... # tenant slicing
openai_locale:vi-VN # locale slicing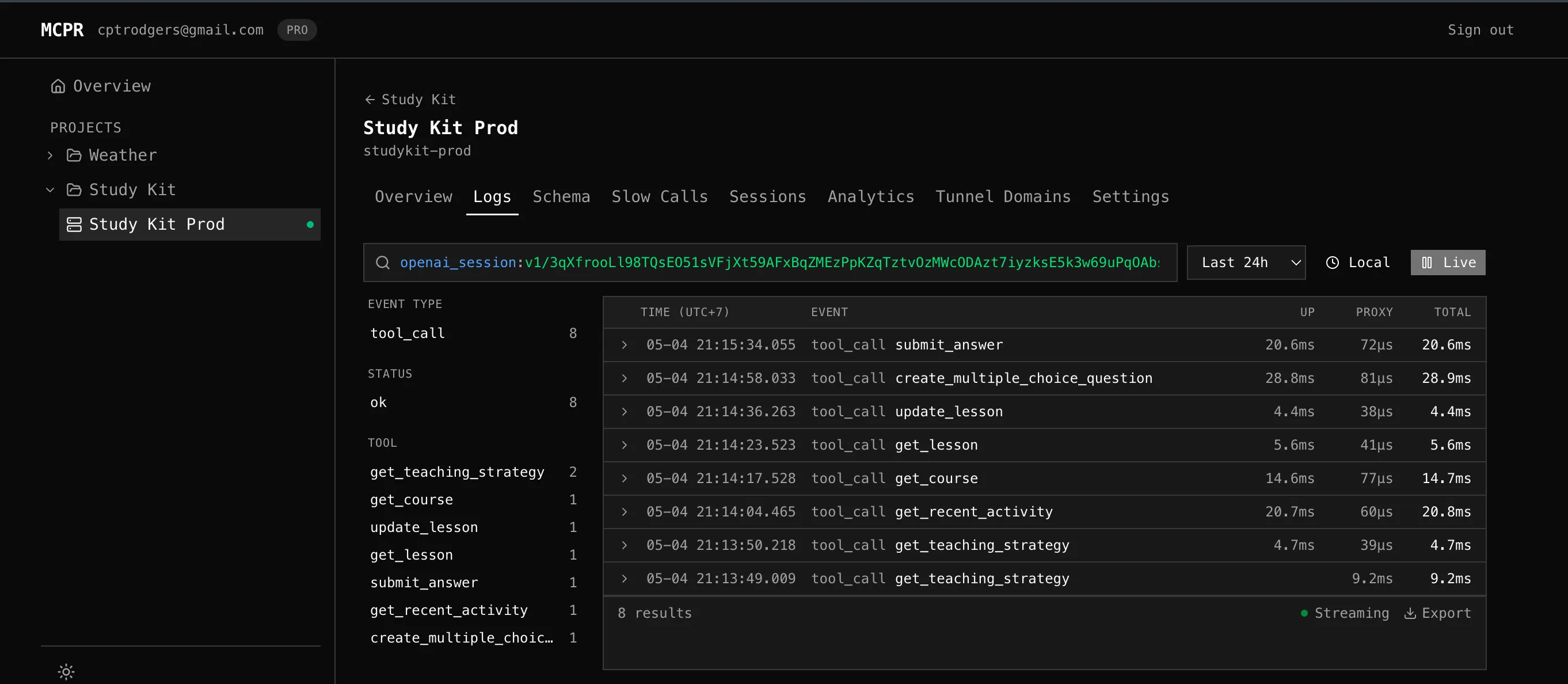
We deliberately didn’t synthesize a unified session ID across the two keyspaces, and we don’t treat any of these as auth. Both columns coexist; you pick the right one per query.
What to do without mcpr
const meta = req.params?._meta ?? {};
log.info({
mcp_session_id: req.headers["mcp-session-id"],
openai_session_id: meta["openai/session"],
openai_subject_id: meta["openai/subject"],
openai_org_id: meta["openai/organization"],
tool: req.params.name,
});Two things to watch for:
- Type tolerance. OpenAI’s spec says strings, but older clients have been seen sending
openai/sessionas a number. Validate before storing. userLocationis geo PII. It includeslatitude/longitudeto four decimal places (~11m precision). Decide your retention before you fill a table.
The takeaway
ChatGPT carries two session identifiers per request, in two completely different places:
Mcp-Session-Id (HTTP header) | _meta.openai/session (JSON-RPC body) | |
|---|---|---|
| Stable across ChatGPT tool calls | No, rotates every call | Yes, stable for the conversation |
| Visible to header-only proxies | Yes | No, requires JSON-RPC parsing |
| Defined by | MCP spec | OpenAI Apps SDK extension |
| Use for grouping ChatGPT activity | Useless | This is the one |
| Use for auth | No | No, hint only |
The reason it’s structured this way isn’t an accident or an oversight. ChatGPT is architected to be stateless across tool calls, the conversation lives above MCP, and _meta is the spec-sanctioned hidden channel for host context. Once you know that, the rest follows: surface _meta.openai/* as typed columns, filter by openai_session_id, and ignore Mcp-Session-Id for ChatGPT entirely.
Claude’s side of this story is shaped differently and we’re still gathering data. When we have something concrete to say about it, that’ll be part 3.
mcpr is an open-source MCP proxy (Apache 2.0). Drop it in front of your MCP server to capture both openai/session and the standard Mcp-Session-Id on every request, then visualize a full ChatGPT conversation in the cloud dashboard even when the MCP session rotates every tool call.
- mcp
- observability
- chatgpt
- openai